There are many git commands that uses
HEADto operate. Some people say it is a pointer by analogy to the concept in programming language, but this is still vague.
There are threads topic 1 topic 2 on Stackoverflow talking about HEAD, it may help us have a better understand of HEAD.
However, having more knowledge of git core internals and concepts will make us better understand how git works as a version control tool, and I am trying to understand HEAD by learning more about git internals.
-
Git is indeed a content-addressable filesystem. We can consider the core of Git as a key-value database.
This means that you can insert any kind of content into a Git repository, for which Git will hand you back a unique key you can use later to retrieve that content.
$ mkdir project && cd $_ # create and enter an empty project directory $ git init # this will initialize an empty database. $ ls -al # and we will find a hidden direcotry named .git .git $ ls -F .git # list the files or direcotries created in .git, including 5 directories and 3 files, and one file name is HEAD. branches/ config description HEAD hooks/ info/ objects/ refs/ $ ls -R .git/objects # and there are two empty folders in ./git/objects/ .git/objects: info pack .git/objects/info: .git/objects/pack:$ echo 'test content' > test $ git add test $ ls -R .git/objects # git add will generate a d6 folder d6 with a file inside it, the filename consitis of 38 digits and letters .git/objects: d6 info pack .git/objects/d6: 70460b4b4aece5915caf5c68d12f560a9fe3e4 .git/objects/info: .git/objects/pack: $ git log # There is no log before a commit is submitted fatal: your current branch 'master' does not have any commits yet$ git commit -m '1st commit' [master (root-commit) 93b8546] 1st commit 1 file changed, 1 insertion(+) create mode 100644 test $ ls -R .git/objects # After a commit is submitted, there are 3 directories containing 3 different files. .git/objects: 3e 93 d6 info pack .git/objects/3e: 69f02f3247843b482cc99872683692999f6703 .git/objects/93: b85460a5bb0aebdb870a3086df9a73d2fba0a1 .git/objects/d6: 70460b4b4aece5915caf5c68d12f560a9fe3e4 .git/objects/info: .git/objects/pack:$ git log # It tells that the status is: HEAD points to master, containing a commit 93b8... commit 93b85460a5bb0aebdb870a3086df9a73d2fba0a1 (HEAD -> master) Author: Username <myemail@email.com> Date: Sat Nov 21 21:58:42 2020 -0800 1st commit
- Then, I do have these questions in mind: why there are 3 different files generated after a commit is submitted? how does git genarate the files and subdirectories?
$ tree .git/objects # we use tree command instead of ls -R to view the directories structure .git/objects ├── 3e │ └── 69f02f3247843b482cc99872683692999f6703 ├── 93 │ └── b85460a5bb0aebdb870a3086df9a73d2fba0a1 ├── d6 │ └── 70460b4b4aece5915caf5c68d12f560a9fe3e4 ├── info └── pack - And why the log message tells current commit seems pointing to another name? what are these files?
commit 93b85460a5bb0aebdb870a3086df9a73d2fba0a1 (HEAD -> master)
-
Git objects and objects inspection via
git cat-filecommandGit stores the content initially — as a single file per piece of content, named with the SHA-1 checksum of the content and its header. The subdirectory is named with the first 2 characters of the SHA-1, and the filename is the remaining 38 characters.
To describe this data model more clearly, the key-value pattern of git database, the following is how the key is generated:
- any piece of user operated content will generate a file, in fact it is a type of git object;
- the content and its header will be used to generate a 40 digits SHA-1 checksum (Hexadecimal);
- the file will be put in a separate subdirecotry inside .git/objects/;
- the subdirectory name is the first 2 characters of the SHA-1 checksum;
- THE file name will be the remaining 38 characters of the SHA-1 checksum.
2.1 generate SHA1 hash string by the SHA-1 digest algorithm from the content
Let us verify the SHA-1 generation algorithm git uses by comparison to the string generated.$ echo "test content" > test $ git add testecho "test content" | git hash-object --stdin d670460b4b4aece5915caf5c68d12f560a9fe3e4or understand it step by step in ruby irb tool:
$ irb irb(main):001:0> content="test content\n" irb(main):002:0> header="blob #{content.length}\0" irb(main):003:0> store=header+content irb(main):004:0> require 'digest/sha1' => true irb(main):005:0> sha1=Digest::SHA1.hexdigest(store) irb(main):006:0> print sha1 d670460b4b4aece5915caf5c68d12f560a9fe3e4=> nil irb(main):007:0>
About the key: the 40 digit SHA-1 hash value
- Then git splits the 40 characters SHA-1 string into two parts, uses the first 2 character as the sub-directory name in .
git/objects/, uses the latter 38 digits as the filename inside the subdirectory; - There will be 256 subdirectories at most (starts from
00toff, 256 subdirectories at most) in.git/objects/, and each sub-directory can hold many files inside. - The files inside each subdirectory have their unique filename, the latter remaining 38 digits of the SHA-1 hash value.
- Git addresses an object by this SHA1-hash value, it will find the correspondent object by mathcing the sub-directory name and the file name inside.
- Why git splits the hash value into two parts? I think using a two-level path structure may help improving index performance as there are too many commits for the large and longterm maintained repository.
About the value: the object (file) with content
- The content of the
storevariable above("test content") is then compressed by git usingzlib, afterward the zlib-deflated content will be write into an object(a blob in this case) on disk, it is the content of each file in the subdirectory.
As the content is compressed, we cannot read the files directly from ./git/objects/subdirectories.
2.2 use
git cat-filecommand to read files in git objects databasegit provides a command to inspect the content in git object database:
git cat-file, it is considered as sort of a Swiss army knife for inspecting Git objects, the syntax used here is:
git cat-file -p 40-characters-SHA-1-checksum
We use it to check the content of these files.$ git cat-file -t d670460b4b4aece5915caf5c68d12f560a9fe3e4 blob $ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4 # This is the result of git add test test content $ git cat-file -t 3e69f02f3247843b482cc99872683692999f6703 tree $ git cat-file -p 3e69f02f3247843b482cc99872683692999f6703 # This is the result of git commit -m "1st commit", a blob object in the tree object 100644 blob d670460b4b4aece5915caf5c68d12f560a9fe3e4 test $ git cat-file -t 93b85460a5bb0aebdb870a3086df9a73d2fba0a1 commit $ git cat-file -p 93b85460a5bb0aebdb870a3086df9a73d2fba0a1 # This is the result of git commit -m "1st commit" tree 3e69f02f3247843b482cc99872683692999f6703 author Username <mymail@email.com> 1606024722 -0800 committer Username <mymail@email.com> 1606024722 -0800 1st commitFrom the the above output, we know that, each action will be tracked via a record object in git database, and we have seen three
blob,treeandcommittypes in git. In fact, there are four types of objects in git: blob, tree, commit, tag.- commit: The commit object represents the snapshot fo current commit, it contains a tree object hash of current commit content, a parent commit hash points to the previous commit, author, committer, date and message.
git logis used to show commits history; - tree: The tree object contains one line per file or subdirectory, with each line giving file permissions, object type, object hash and filename. Object type is usually one of “blob” for a file or “tree” for a subdirectory;
- blob: The blob object contains the file snapshot;
- tag: It is another type which used for annotated tags.
And
git logcommand output a commit, the same key as the last commit 93b85460a5bb0aebdb870a3086df9a73d2fba0a1; meanwhile, we see that the (HEAD -> master). We knowmasteris our current branch, and litteralyHEADis something currently pointing to master branch. so what isHEADand why does git needHEAD? -
Git references
As the SHA-1 hash value is too long for users to remember, shortcuts or easy ways to find some special commits in git repo branches or tags are necessary. git uses
referencesorrefsto achieve this.- A reference is a file with a simple name stores a commit SHA-1 value, so that users could use this simple name rather than the raw SHA-1 value to locate the commit.
- In other words, reference is another way to use SHA-1 value as the key to index git objects, which uses a simple name string instead.
- References are used for special use cases like accessing tip of branches, tags.
Git put refs inside
.git/refsdirectory:- the latest commit of each branch is stored in
./git/refs/head/directory - new created repo will have a default reference named
master - the content of a ref file is a SHA-1 hash key
$ tree .git/refs .git/refs ├── heads │ └── master └── tags $ git checkout -b develop Switched to a new branch 'develop' ╭─/project ‹develop› ╰─$ tree .git/refs .git/refs ├── heads │ ├── develop │ └── master └── tags$ cat .git/refs/heads/master 1 ↵ 93b85460a5bb0aebdb870a3086df9a73d2fba0a1 $ cat .git/refs/heads/develop 93b85460a5bb0aebdb870a3086df9a73d2fba0a1
Git refs can be created or updated by changing the SHA-1 value in the refs file.
- When creating a new branch via command
git branch <branch>orgit checkout -b <branch>etc. commands, git will runupdate-refcommand to add the SHA-1 of the last commit of the branch user are on into the new reference file(by default using the branch name). - It is not recommended to update the refs by adding/editing reference files manualy. The following commands have the same effects on updating/creating a reference.
$ git update-ref .git/refs/heads/develop 93b85460a5bb0aebdb870a3086df9a73d2fba0a1 # use the commit 93b854 to create a branch $ git update-ref .git/refs/heads/develop 93b854 # we can use the first 6 characters to replace the long SHA-1 $ git branch develop $ git checkout -b develop git checkout commitSHA-1will update the head reference of a existing branch.$ git checkout commitId # when user is on develop branch $ git update-ref .git/refs/heads/develop commitId # same effect as above
-
HEAD reference and the detached HEAD state
4.1 The HEADReferences are shortcuts to access the tip of branches or tags,
HEADis a file in the root of .git directory, it is a special type of reference, it points to the last commit/the tip of current working branch by default.Usually, the
HEADfile is a symbolic reference to the branch we’re currently on. By symbolic reference, we mean that unlike a normal reference, it contains a pointer to another reference not a SHA-1 value. It can also be used to move to different points in history and work from there.# the following output is from another git repo $ cat .git/HEAD ref: refs/heads/master $ cat .git/refs/heads/master 870a3086df9a73d2fba0a193b85460a5bb0aebdb $ git checkout develop $ cat .git/HEAD ref: refs/heads/develop $ cat .git/refs/heads/develop d9511748b6a8d7c00352ae138f5d1a63ee07eae0From the above, we can see that: HEAD-->branch head-->last commit
- HEAD points to current branch head, and the branch head points to the last commit of its own;
- HEAD eventually points to the last commit in a branch;
- HEAD changes when we switch to another branch.
So, essentially, HEAD points to a commit, then we may have these questions:
- Why does not git let HEAD point to the commit directly? The answer is that git adds the HEAD reference to distinguish currrent working branch when multiple branches exist in a repository. Git cannot identify which branch is working on if HEAD points to the branch commit directly when we switch to a different branch. while using HEAD reference, switching of branch will update the HEAD reference to the new branch simultaneously, and we can easily use HEAD to locate current working branch.
- Is it possible to let HEAD point to a specific commit directly? YES, it is the detached HEAD state.
4.2 The detached HEAD state
git checkout branchnamewill let theHEADpoint to the targeted branch(tip commit of the branch)
git checkout commitIdwill letHEADpoint to the commit directly, and make HEAD in a detached state if the commit is not the tip of the branchHowever, when we checkout a tag, commit, or remote branch without binding a branch, this will put the repository in a "detached HEAD" state. It means that HEAD file will contain the SHA-1 value of a git object rather than the path of another reference at this time. Thus,
HEADbecomes a normal reference, it refers to a specific commit, as opposed to referring to a named branch. As the detached HEAD will not pointer to any other references in git, commits in this state will not be tracked by a specific branch, and they will be discarded by git at later time. By creating new branch with the detached commit, we can keep it tracked or merged to other branches and avoid change loss.$ git branch temp commitId $ git checkout master $ git merge temp $ git branch -d temp4.3 HEAD, HEAD^, HEAD~
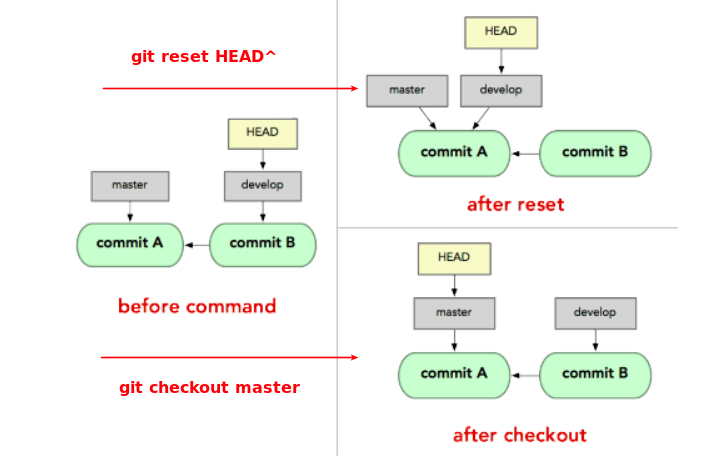
If we use
git reset HEADcommand, the working branch will not update the head reference as it is currently pointing to the branch head; however, it will reset the index area;git resethas different options that will have different effect on working tree, index and commit history;
If we usegit reset HEAD^command, the working branch will update the head reference, andHEADwill move and point to the previous commit.- HEAD: HEAD^0 or HEAD~0, by default, HEAD reference points to the tip(latest snapshot/commit) of current working branch;
- HEAD^: aka HEAD^1, the previous commit of the working branch;
- HEAD~: aka HEAD~1, same as above;
4.4 HEAD^n, HEAD~n(when n>1)
- ^ is used to select a path when it enconters a merged commit, ^1 or ^2 will go back to different route/branch before the merged commit;
- ~ is used to go back on a selected route, ~n is to go back n commits;
- if there is no merge in the previous n commits, the two have the same effect.
- if there is a merged commit in the previous n commits, use ^2 to pick a route(branch) that is merged from, use ^1 to follow current working branch where other branch is merged into;
So, use steer a car in reverse by analogy:
- ^ acts as a steering wheel to pick a route/branch when the back route come to a merging point;
- ~ is used to go straight way (back) on the same route without changing the direction or by ignoring to change to another merged in route;
- if there are no merging point(it is a single way) on the way, there is no need to pick a route, ^n has the same effect with ~n.
4.5 Other types of HEAD
$ ls -1 .git | grep HEAD FETCH_HEAD HEAD ORIG_HEAD- HEAD: The current ref that we’re looking at. In most cases it’s probably refs/heads/master or point to the working branch;
- FETCH_HEAD: The SHAs of branch/remote heads that were updated during the last git fetch;
- ORIG_HEAD: When doing a merge, this is the SHA of the branch you’re merging into;
- MERGE_HEAD: When doing a merge, this is the SHA of the branch you’re merging from;
- CHERRY_PICK_HEAD: When doing a cherry-pick, this is the SHA of the commit which you are cherry-picking.
- ...
However, all these xxx_HEAD point to the latest commit by default.
-
Summary
To sum up, we can say that:- Git uses a key-value object data model to store user changes in its own database;
- All changes in git are tracked by snapshots, stored in git objects(blob, tree, commit, tag) and managed by git database;
- The key for retrieving an object is a 40-digit SHA-1 hash value generated by the changed content;
- Git uses references to access special commits object: last commit of each branch(branch heads), the tagged commit of a tag,;
HEADis ususally a symbolic reference to the branch we’re currently on, it contains a pointer(actually a path) to another reference(e.g. usually is the branch head: the last commit on this branch);HEADwill be detached to branches when checking out to a commit directly, it becomes a normal reference, new commits will not be tracked by branches;- There are other types of
HEADreferences in git for special use case as well.
-
Readings
- https://git-scm.com/book/en/v2/Git-Internals-Git-References
- https://initialcommit.com/blog/Learn-Git-Guidebook-For-Developers-Chapter-2
- https://reference.bytefusion.de/2019/07/14/how-git-uses-key-value-store/
- https://matthew-brett.github.io/curious-git/git_object_types.html
- http://shafiul.github.io/gitbook/1_the_git_object_model.html
- https://www.cnblogs.com/LXL616/p/10774928.html
- https://www.cnblogs.com/kekec/p/9248487.html
Comments