We had experienced a very weird phenominon when accessing our new mobile web application on production environment. It turns out that the issue is caused by an un-recommended kernel setting which is really difficult to figure out intuitionally.
1. Issue phenomenons and troubleshooting process
The related stack is:
- Frontend: Reactjs + Webpack
- Backend: Nginx (Web server) + Nodejs + express (Api server) + MySQL + Other Web services
- Cloud Hosting on CentOS Linux
1.1 Failure: web app cannot load successfully sometimes
During the first few days' testing, we found that:
- Some new-model iPhone devices(like iPhone X, 11, 12) failed to load the web applicatoin, no matter use WIFI or 4G LTE network to test. Sometimes, it cannot be fully loaded and stuck at banner carousel loading stage, sometimes, the whole page cannot be opened and left a blank page until getting a timeout of server access;
- However, Android, Mac devcies had rare chance of failure.
- No 404, 502... HTTP status exception
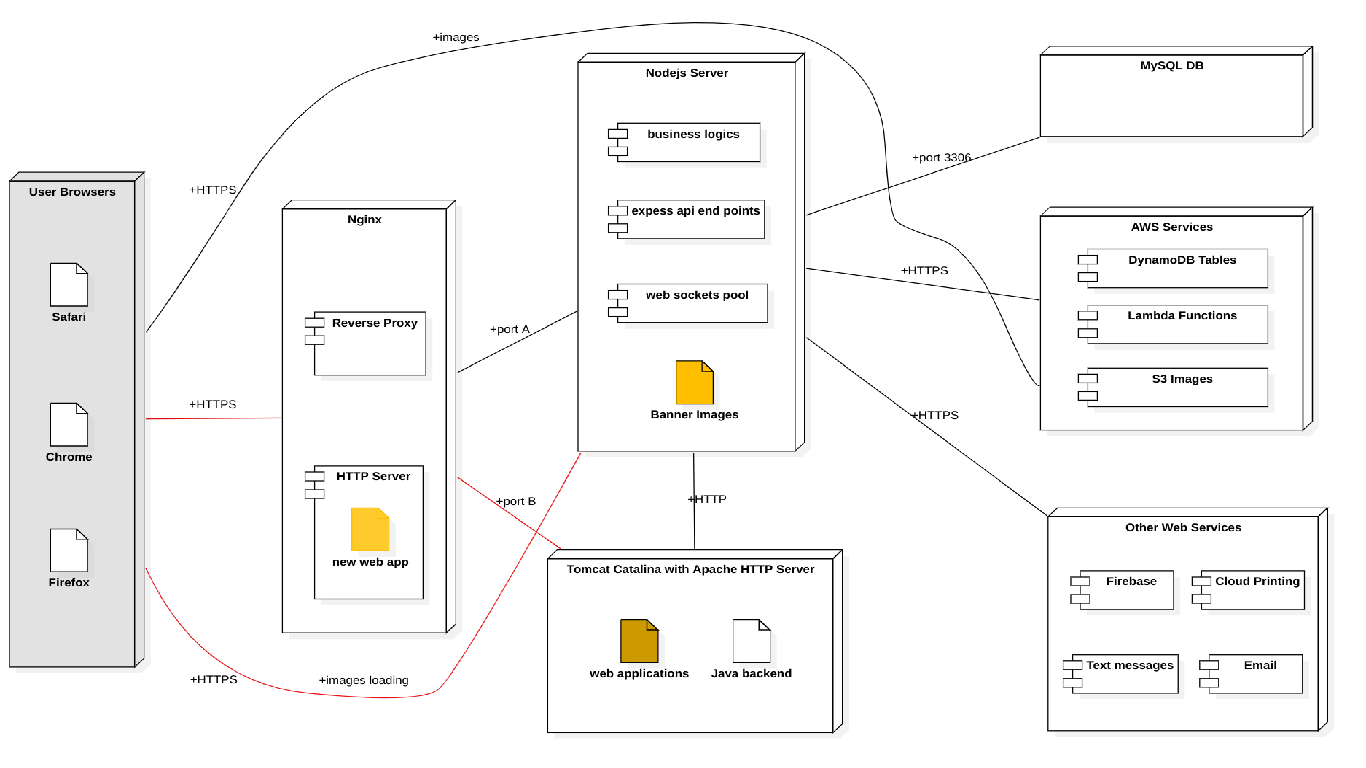
Following is our applicatoins deployment view, note that:
- We all thought the issue came from the new developed web application at first.
- The red line routes to other web applications were also unstable, and this was found afterward.
1.2 First fix try: web app optimization ---> not working
Initially, we took it granted that it is caused by the web app, and it should be optimized to acceralate first page loading as it's a SPA, like:
- To compress the images resources of carousel to smaller size as they are too large in size;
- To migrate images to AWS S3 storage buckets or add a CDN accelerator to enhance load speed;
- To minize production code bulnder size by excluding unused package files; and compress the bunldler to gzip format to reduce resouces load size;
- Anything wrong with new implemented web socket communication?
These aspects sound fairly reasonable. Then I did some optimization like use gzip to compress the code, comment out the carousel module to test load result, however, the issue still existed.
Then I tried to do more tests in order to exclude unrelated guess, to find out on which end does the issue originate from, and we found that:
- Failures also exist when accessing other web applications;
- Failures still exist when using iPhones to test.
So it implied that:
- the server machine we host our web application may have some wrong configuration;
- Any imcompatibilites issue of new iPhone browsers(Safari) with Reactjs or packages dependencies?
1.3 Further diagnosis: HTTP Requests package loss, ERROR_CONNECTION TIMEOUT
I cannot persuade myself that the iPhone/iOS has problem of running Reactjs web application. And these devices can access other websites smoothly. So I began to check the server configuration but didn't have any obvious targets in mind.
-
First, I tried to find a clue from nginx access logs. Fortunately I found that: there were no logs generated or only part of requests logs generated when an access failure happened. This finding changed my troubleshooting direction. It means that there were packages loss during the access.
tail -f /var/log/nginx/access.log
-
I also used Chrome dev tools network panel to check the requests after the URL was input and sent from address bar. The following picture shows a completely failed access(no requets send out) from the server, which ended up with an
ERROR_CONNECTION_TIMEOUTerror.
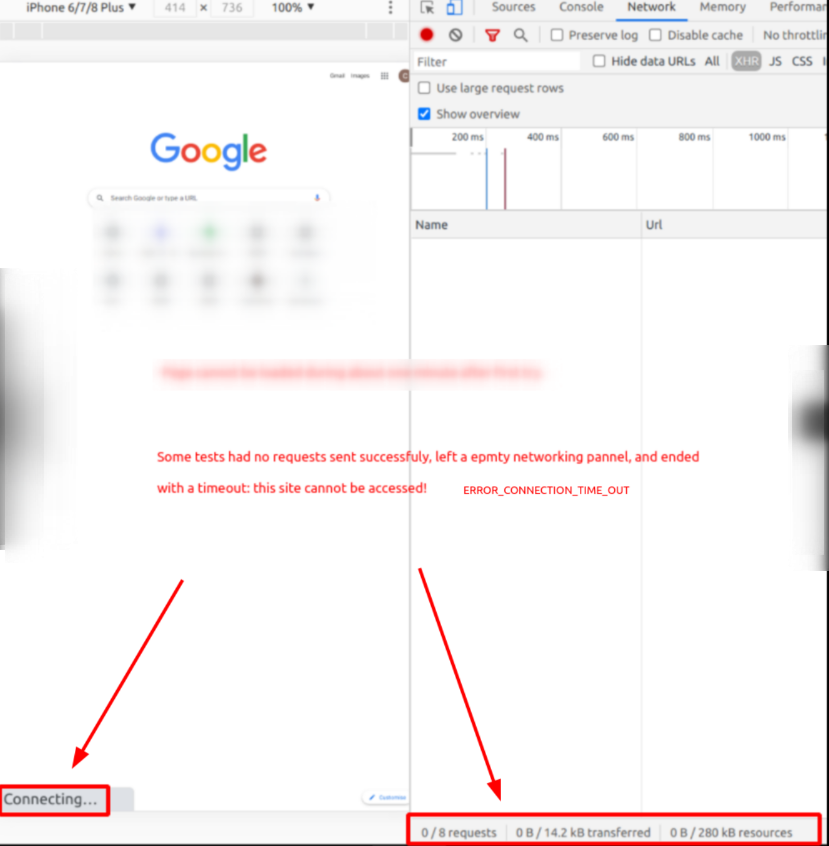
But... what caused the package loss? unstable networking of carrier? however, why some devices barely failed?
1.4 More details found: there is a 60 seconds failure recovery
From my own experience, finding details or specific charateristic of bugs or failures is important to identify where issues come from if we don't know where to go.
So, we did more tests, and another new phenomenon was put up: failures happened after the first successful access on some devices, sometimes the page cannot load at all, and continuous re-tries always failed. however, the failures will auto-recover after around 1 minute on the failed phone.
As 1 minute is 60 seconds, the number gave me a keyword in mind: timeout for searching where issue comes from.
So, which time related option or configuration of the HTTP server impact this?
Although there are keepalive_timeout, ssl_session_timeout, proxy_read_timeout etc in the nginx config file, I think there is no connection to this issue, becuase I cannot find corresponding HTTP requests hit nginx from the nginx log diagnosis.
As HTTP is an application protocol over TCP(layer 4) which works at the 7th layer of OSI model, technically, the nigix web or proxy server works at this layer as well.
As browser requests to nginx server(using port 443) didn't show up at all or only came up few from the access logs when an access failed, this means some connections are not established at the lower layer (TCP layer) as expected..
So I turned to check the server network status.
netstat -an
I found that there is no TIME_WAIT connections, this is not common. TIME_WAIT is one stages of socket closing process, as connections are established and closed quite often for server and clients constantly, there should exist some TIME_WAIT connections as we have several online production application and service running.
netstat -an | grep TIME_WAIT | wc -l 0
Initially, I didn't think this related to the cause of package loss. But this finding gave me some curiosity. why there is no TIME_WAIT status connections here?
The answer is the server enabled TCP socket recycle.
1.5 solution: turn off kernel tcp socket recycle
cat /proc/sys/net/ipv4/tcp_tw_recycle 1
From above, I saw that the server enabled TCP socket recycle.
echo 0 > /proc/sys/net/ipv4/tcp_tw_recycle # this will turn off tcp recycle
After I turned off this network configuration option, everything goes back to normal, no more failed access to the new web application! The solution is quick and effective and a little unexpected to me.
1.6 Questions need to be answered
Alghough I found the fixed to this issue, I still have many questions not figured out in my mind.
- Why the enabled
tcp_tw_recyclesocket option cuases this unstable access? and why it was enabled before? - Why the failures can be recovered in one minute(60 seconds)?
- Why the issue happens on some devices frequently?
2. Under the hood
2.1 why TCP connection close needs TIME_WAIT?
It's konwn that TCP is a duplex protocol which has retransimission and sequence/order control to provide reliable data delivery. The design of time wait has two main purposes during the tcp close procedure:
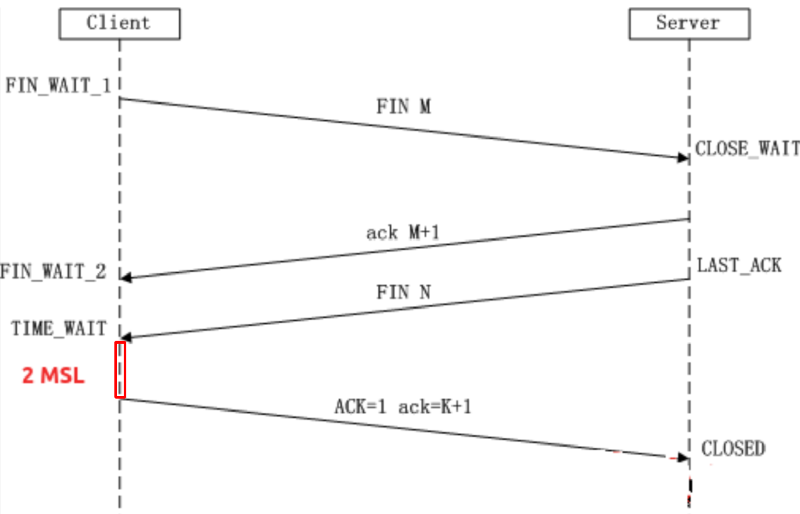
- To ensure client-server close the socket at both sides. as the client's last
ACKpackage may be lost and the server side doesn't get it, so the server will re-send aFINto the client to tell the client end the connection. Without aTIME_WAIT, the client will close the connection instantly:- as the server is in
LAST_ACKstatus and waiting for aACKfrom client, it will re-send aFINto the client and expect to ask the client to ackknowlege. As the client is closed, it will take thisFINas un-recognized package and response aRSTas well, thus, the server cannot terminate a connection normally. - meanwhile, if the client send a
SYNto the client to establish a new connection, however, the server is still waiting aACK, it will takeSYNas a un-recognized package then response aRSTto the client. This leads to new connection cannot be created normally.
- as the server is in
- To avoid mis-using the delayed re-transimission package of a closed connection in the new created connection.
TIME_WAIT. A new connection will be created with the same port of the closed connection, if there is a re-transimission package from last closed connection, and concidentally matched the sequence, it will be considered as a right package to recieve. However, this is wrong as its not from the same connection. A reasonableTIME_WAITwill avoid data mis-using in new created connection before the re-transmission package arrives.
2.2 what is the recommended TIME_WAIT duration?
From RFC 793, Page 22, it defines the TIME_WAIT to last 2MSL(Max Segment Lifetime). Maximum segment lifetime is the time a TCP segment can exist in the internetwork system.
TIME-WAIT STATE : The only thing that can arrive in this state is a retransmission of the remote FIN. Acknowledge it, and restart the 2 MSL timeout.
It defines a 2 MSL time wait(a retransmission of FIN and the last ACK) will ensure safe close of a connection. As it was defined in 1981, the MSL is suggested to be 1 minute, and TIME_WAIT is 2 minutes. Nowadays, the transimission speed is much faster than before, the MSL in some impelmentation of system varies, it is 30s defined in Linux kernel(thus, a 60s duration TIME_WAIT).
cat /proc/sys/net/ipv4/tcp_fin_timeout # 60 seconds by default in Linux 60
2.3 why tcp_tw_recycle is introduced? what's the side effects?
As TIME_WAIT will last 2*MSL before a connection is closed, there would be TIME_WAIT connection exsit in our system, especially in high-concurrency server systems. However, people think these will take system resources, like:
- occupy the ports which are not released instantly
- additional memory and CPU usage
In order to get a better use of system resources, people want to terminates this connections more instantly, then tcp_tw_recycle is introduced.
cat /proc/sys/net/ipv4/tcp_tw_recycled # disabled by default 0
When this feature is enabled, the TIME_WAIT timeout will not take effect, and the connection will be closed after the retransmission timeout (RTO) interval which is computed from the RTT and its variance, which is very short.
Meanwhile, in order to avoid mis-using of old re-transmission packages in new connection as TIME_WAIT supports, it requires another tcp_timestamps enabled. This helps a connection to distinguash packages from different sockets via timestamp comparsion instead of the TIME_WAIT. With tcp_timestamps enabled, the package's timestamp of sending time will be saved in the package. It defines some rule to determine whether the package is old cannot be used. Thus, packages with old/smaller timestamps will be considered as the previous old package and ignored. This mechanism is called Per-host PAWS(Protect Against Wrapped Sequences) which defined in RFC 1323.
cat /proc/sys/net/ipv4/tcp_timestamps # enabled by default 1
However, this is not accurate and too aggressive, and it may mis-ignore some packages from clients from a NAT network. As it use the IP(per host) to identify a connection, as devices in NAT are using the same IP, but they have different clock(aka. timestamps), all the connections from the same NAT clients will be considered as the single client , and the timestamps from different clients will not keep a increased number, thus these packages can be easily taken as wrong sequence packages and be ignored mistakenly. This will lead connection establishment failure of devices in the NAT, and only the clients with similar increased range number will be accepted and keep alive. Some material says it has 50% possibility of failure, and only one device can be established with the server at the same time. However, my understanding is that, whether a device can be kept in the connection is up to the timestamp of the package is newer or outdated compared to the previous package when it transmits data, I found sometimes two or devices can work for a period time without obvious timeout or disconnection.
2.4 why some of the devices can access the server and some devices fails to connect?
From the above, we know that devices in the NAT will encounter packages drop or rejection when tcp_tw_recycle is enabled, as packages may be taken as disordered. This leads many unstable accesses of our application, as many HTTP requests(over TCP) cannot be established as expected.
For most occasions, user devices are behind/in a NAT environment, like in a WIFI or a mobile carrier service, multiple devices will use one external IP to access the web server instead each clients hold a unique IP address. The follwing are packages captured from the server when browser had failures from the server by tcpdump.
tcpdump -w connection.pcap host 24.86.4.164 # 24.86.4.164 is the external IP of office WIFI, not the device private IP allocated from a DHCP server.
It shows that there are many re-transmissions packages(in black), and tcp sockets establish sequences SYN, ACK, FIN packages(in gray) are not as normal.
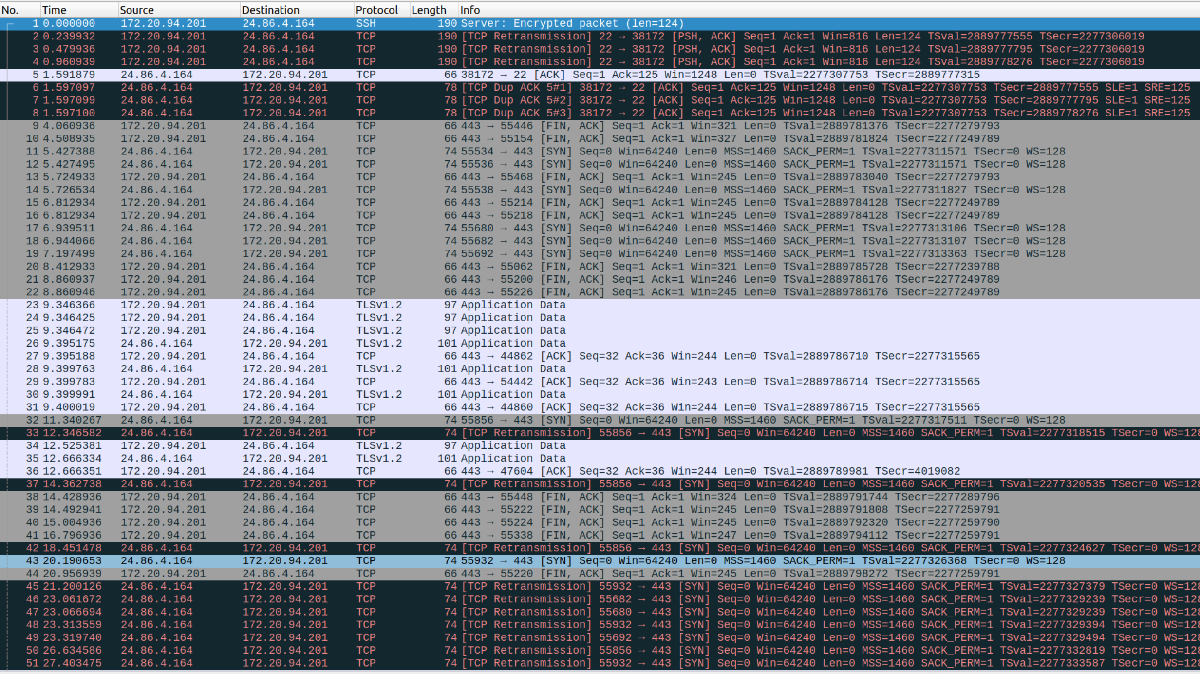
There are many SYN requests not responsed, and also caused many SYN re-transmission packages, some access are not established.
2.5 why the failure of connection recovery time is 60 seconds?
This PAWS mechanism is implemented in the kernel function in tcp_metrics.c
bool tcp_peer_is_proven(struct request_sock *req, struct dst_entry *dst, bool paws_check)
{
struct tcp_metrics_block *tm;
bool ret;
if (!dst)
return false;
rcu_read_lock();
tm = __tcp_get_metrics_req(req, dst);
if (paws_check) {
if (tm &&
(u32)get_seconds() - tm->tcpm_ts_stamp < TCP_PAWS_MSL &&
(s32)(tm->tcpm_ts - req->ts_recent) > TCP_PAWS_WINDOW)
ret = false;
else
ret = true;
} else {
if (tm && tcp_metric_get(tm, TCP_METRIC_RTT) && tm->tcpm_ts_stamp)
ret = true;
else
ret = false;
}
rcu_read_unlock();
return ret;
}
We can see by reading the source code: there are three combined conditions to identify a wrong package:
- The peer/host has enabled timestamp;
- The peer's has previous package transferred to the server in MSL time (60s on Linux, value of macro TCP_PAWS_MSL);
- The peer's connection timestamp is less greater than previous package's , and the difference is greater than TCP_PAWS_WINDOW(value is 1).
tm && (u32)get_seconds() - tm->tcpm_ts_stamp < TCP_PAWS_MSL && (s32)(tm->tcpm_ts - req->ts_recent) > TCP_PAWS_WINDOW)
When all the three conditions are met, the coming package will be taken as a stale package and be dropped. By using this mechanism, the kernel expects to do a more reasonable fast recycle of the old TCP connections.
From the capture screenshot above, we can see many SYN packages were dropped.
Let's see if these conditions can be met by analyzing the captured packages from the screenshot above(in section 4):
- check if the timestamp option is enabled:
cat /proc/sys/net/ipv4/tcp_timestamps 1
In fact, this is enabled by default, so the first condition is met. Once enabled, the packages will has a TSVar value to record the timestamp(generated by CPU clock) when the package is sent from the client host.
- There are many
SYNconnection requests coming from a peer host with IP 24.86.4.164, all the packages are sentin 1 minutes(53s), then this condition is met as well; - The timestamps values(TSval) of each two adjacent packages from the same peer are not in a increased order: A pit that I haven't captured the right-time packages to illustrate this, but I think this is really easy to happen for devices in NAT network.
3. Wrap Up
Gotcha: NAT + Per-host PAWS + Linux Kernel Versoin < 4.11 --> unexpcected failure of network connection/unstable site access/60s access interruption
As devices in NAT network shares a common IP address, but the generate different package timestamp, those timestamps are likely to have a strictly increased sequence when they are generated by different devices. So when we use multiple devices from home, office WIFI network, or even use the data plan of celluar network, our devices are behind a NAT network for most occassions. As tcp_tw_recycle is aggressive, it will drop many packages when they don't match Per-host PAWS rules, especially it's likely to happen to vistors who are behind a NAT network. And when most SYN packages from different end-user are dropped, the services provided will not be stable, causing client visit timeout or failure issue which is very difficult to diagnose.
Thus, if the sites are hosted on a server which enabled tcp sockets fast recycle, we will endure a unstable access to the sites.
-
Lower version of Linux kernel has
tcp_tw_recycleoption: Following is the server version check from our Nginx server, which unfortunately has this option and enabled before the issue is fixed.uname -r 3.10.0-957.1.3.el7.x86_64 ls /proc/sys/net/ipv4/tcp_tw* /proc/sys/net/ipv4/tcp_tw_recycle /proc/sys/net/ipv4/tcp_tw_reuse cat /proc/sys/net/ipv4/tcp_tw_recycle 1 cat /proc/sys/net/ipv4/tcp_timestamps 1
-
tcp_tw_recycle not exists on latest Linux kernel: As this feature has proven to be not a good design, it is removed in the new version kernel.
[ec2-user@ip-172-31-25-0 ~]$ uname -r 4.18.0-240.15.1.el8_3.x86_64 [ec2-user@ip-172-31-25-0 ~]$ ls /proc/sys/net/ipv4/tcp_tw ls: cannot access '/proc/sys/net/ipv4/tcp_tw': No such file or directory [ec2-user@ip-172-31-25-0 ~]$
-
Linux documentation description (
man 7 tcpand searchtcp_tw_recycle)tcp_tw_recycle (Boolean; default: disabled; Linux 2.4 to 4.11)
Enable fast recycling of TIME_WAIT sockets. Enabling this option is not recommended as the remote IP may not use monotonically increasing timestamps (devices behind NAT, devices with per-connection timestamp offsets). See RFC 1323 (PAWS) and RFC 6191.
4. Readings
Following are materials I have read to explore the root cause of our issue. These docomentations, articles or forum threads described or discussed on TCP_TIMEWAIT, Per-host PAWS Mechanism, NAT Problem.
- https://datatracker.ietf.org/doc/html/rfc793#page-23
- https://datatracker.ietf.org/doc/html/rfc1323#page-17
- https://vincent.bernat.ch/en/blog/2014-tcp-time-wait-state-linux
- https://www.speedguide.net/articles/linux-tweaking-121
- http://www.serverframework.com/asynchronousevents/2011/01/time-wait-and-its-design-implications-for-protocols-and-scalable-servers.html
- https://linux.kernel.narkive.com/nmNNOHlX/patch-ipv4-mitigate-an-integer-underflow-when-comparing-tcp-timestamps
- https://www.programmersought.com/article/4065751823/
- https://stackoverflow.com/questions/8893888/dropping-of-connections-with-tcp-tw-recycle
- https://www.titanwolf.org/Network/q/7c6ea699-7d93-434d-b2dc-2754ac9af529/y
- https://elixir.bootlin.com/linux/v3.10/source/net/ipv4/tcp_metrics.c#L536
- https://titanwolf.org/Network/Articles/Article?AID=177f8ad9-4b44-4aa3-ae24-0864664e7103#gsc.tab=0
- https://www.alibabacloud.com/blog/595251
- https://www.cnblogs.com/kevingrace/p/9988354.html
- https://www.cnblogs.com/zhenbianshu/p/10637964.html
- https://zhuanlan.zhihu.com/p/35684094
Comments